ReDial Dataset
Datasheet
- Motivation for Creating ReDial
- Dataset Composition
- Data Collection Process
- Data Preprocessing
- License
- Maintenance
- Legal + Ethical Considerations
Motivation for Creating ReDial
Why was ReDial Created?
The dataset allows research at the intersection of goal-directed dialogue systems (such as restaurant recommendation) and free-form (also called “chit-chat”) dialogue systems.
Which other tasks can it be used for?
In the dataset, users talk about which movies they like and which ones they do not like, which ones they have seen or not etc., and labels which we ensured agree between the two participants. This allows to research how sentiment is expressed in dialogues, which differs a lot from e.g. review websites.
The dialogues and the movies they mention form a curious bi-partite graph structure, which is related to how users talk about the movie (e.g. genre information).
Ignoring label information, this dataset can also be viewed as a limited domain chit-chat dialogue dataset.
Who Funded the Creation of ReDial?
The dataset collection was funded by Google, IBM, and NSERC, with editorial support from Microsoft Research.
Support or Contact
You can reach out to us via the redial-dataset google group:
Dataset Composition
Structure
The dataset is published in the “jsonl” format, i.e., as a text file where each line corresponds to a Dialogue given as a valid JSON document.
A Dialogue contains these fields:
conversationId: an integerinitiatorWorkerId: an integer identifying to the worker initiating the conversation (the recommendation seeker)respondentWorkerId: an integer identifying the worker responding to the initiator (the recommender)messages: a list ofMessageobjectsmovieMentions: a dict mapping movie IDs mentioned in this dialogue to movie namesinitiatorQuestions: a dictionary mapping movie IDs to the labels supplied by the initiator. Each label is a bool corresponding to whether the initiator has said he saw the movie, liked it, or suggested it.respondentQuestions: a dictionary mapping movie IDs to the labels supplied by the respondent. Each label is a bool corresponding to whether the initiator has said he saw the movie, liked it, or suggested it.
Each Message contains these fields:
messageId: a unique ID for this messagetext: a string with the actual message. The string may contain a token starting with@followed by an integer. This is a movie ID which can be looked up in themovieMentionsfield of theDialogueobject.timeOffset: time since start of dialogue in secondssenderWorkerId: the ID of the worker sending the message, eitherinitiatorWorkerIdorrespondentWorkerId.
The labels in initiatorQuestions and respondentQuestions have the following meaning:
suggested:0if it was mentioned by the seeker,1if it was a suggestion from the recommenderseen:0if the seeker has not seen the movie,1if they have seen it,2if they did not sayliked:0if the seeker did not like the movie,1if they liked it,2if they did not say
Dataset Size
The dataset contains a total of 11348 dialogues, 10006 for training and model selection, and 1342 for testing.
Dependence on External Sources
We do not provide explicit links to movie synopsis, actors staring in the movies, or other meta-data.
Recommended Splits
We provide two download files, one for training and model selection, and one for testing. The test set was generated by a disjoint set of workers at a later time, so some movies in the test set may not have been released at the time of the training set collection.
Data Collection Process
Here we formalize the setup of a conversation involving recommendations for the purposes of data collection. To provide some additional structure to our data (and models) we define one person in the dialogue as the recommendation seeker and the other as the recommender.
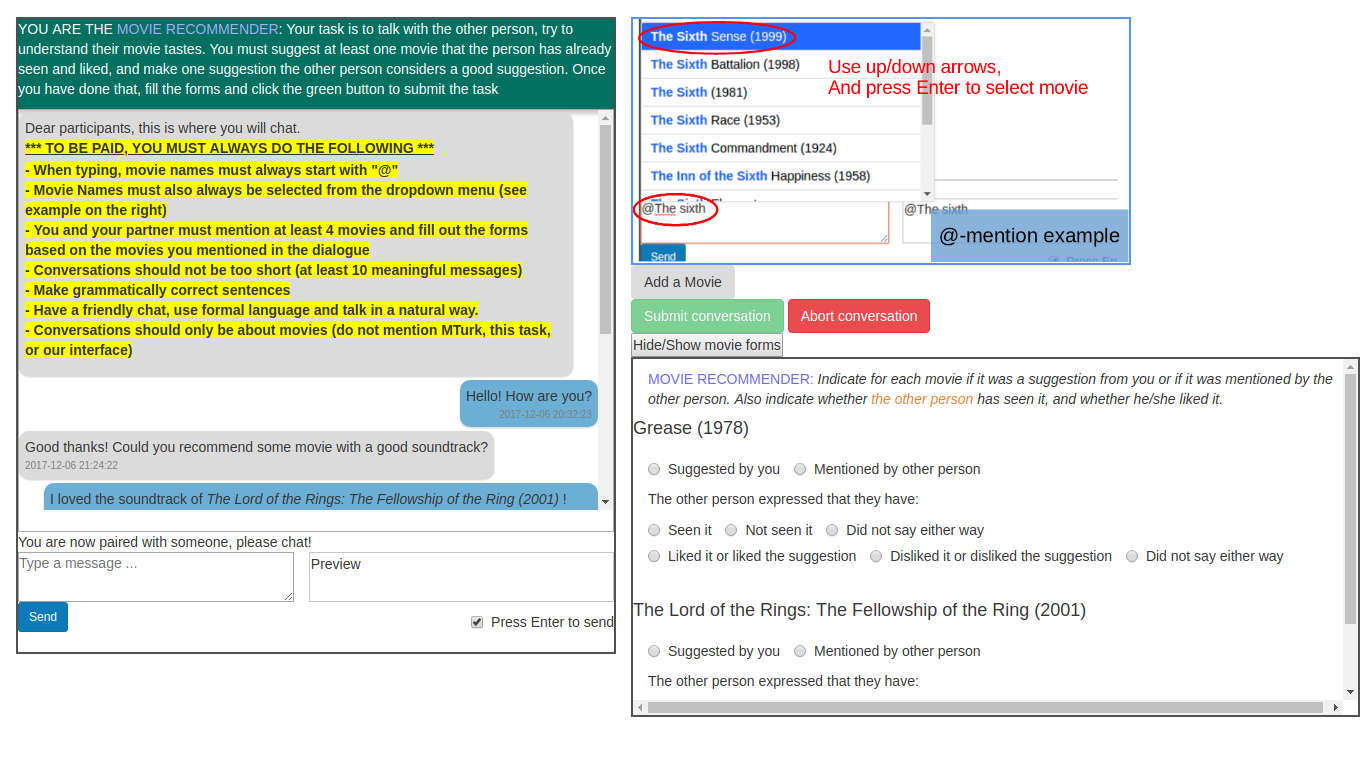
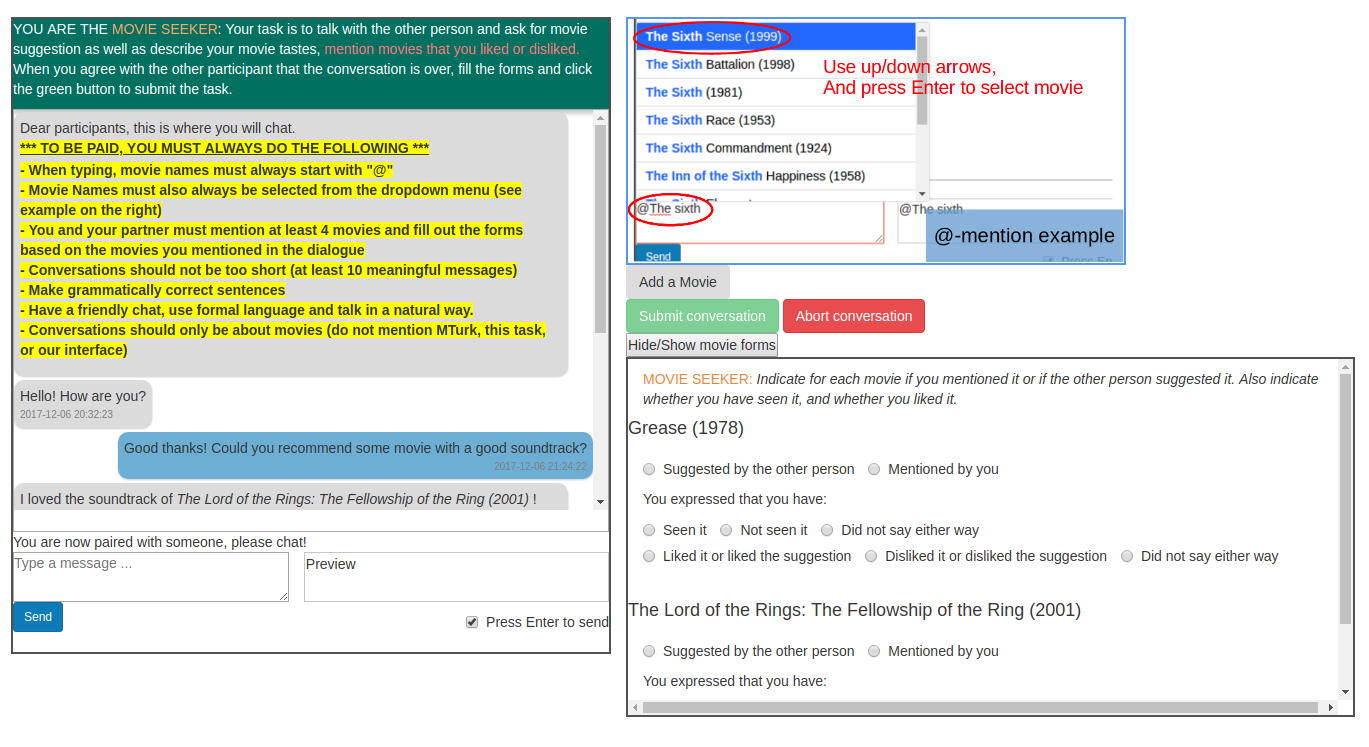
To obtain data in this form, we developed an interface and pairing mechanism mediated by Amazon Mechanical Turk (AMT).
We pair up AMT workers and give each of them a role. The movie seeker has to explain what kind of movie he/she likes, and asks for movie suggestions. The recommender tries to understand the seeker’s movie tastes, and recommends movies. All exchanges of information and recommendations are made using natural language.
We add additional instructions to improve the data quality and guide the workers to dialogue the way we expect them to. Thus we ask to use formal language and that conversations contain roughly ten messages minimum. We also require that at least four different movies are mentioned in every conversation. Finally, we also ask to converse only about movies, and notably not to mention Mechanical Turk or the task itself.
In addition, we ask that every movie mention is tagged using the ‘@’ symbol. When workers type ‘@’, the following characters are used to find matching movie names, and workers can choose a movie from that list. This allows us to detect exactly what movies are mentioned and when. We gathered entities from DBpedia that were of type http://dbpedia.org/ontology/Film to obtain a list of movies, but also allow workers to add their own movies to the list if it is not present already. We obtained the release dates from the movie titles (e.g. http://dbpedia.org/page/American_Beauty_(1999_film), or, if the movie title does not contain that information, from an additional SPARQL request. Note that the year or release date of a movie can be essential to differentiate movies with the same name, but released at different dates.
We will refer to these additional labels as movie dialogue forms. Both workers have to answer these forms even though it really concerns the seeker’s movie tastes. Ideally, the two participants would give the same answer to every form, but it is possible that their answers do not coincide (because of carelessness, or dialogue ambiguity). The movie dialogue forms therefore allow us to evaluate sub-components of an overall neural dialogue system more systematically, for example one can train and evaluate a sentiment analysis model directly using these labels. %which could produce a reward for the dialogue agent.
In each conversation, the number of movies mentioned varies, so we have different numbers of movie dialogue form answers for each conversation. The distribution of the different classes of the movie dialogue form is shown in Table 1a. The liked/disliked/did not say label is highly imbalanced. This is standard for recommendation data, since people are naturally more likely to talk about movies that they like, and the recommender’s objective is to recommend movies that the seeker is likely to like.
Who was Involved in the Data Collection Process?
For the AMT HIT we collect data in English and chose to restrict the data collection to countries where English is the main language. The fact that we pair workers together slows down the data collection since we ask that at least two persons are online at the same time to do the task, so a good amount of workers is required to make the collection possible. Meanwhile, the task is quite demanding, and we have to select qualified workers. HIT reward and qualification requirement were decisive to get good conversation quality while still ensuring that people could get paired together. We launched preliminary HITs to find a compromise and finally set the reward to $0.50 per person for each completed conversation (so each conversation costs us $1, plus taxes), and ask that workers meet the following requirements: (1)~Approval percentage greater than 95, (2)~Number of approved HITs greater than 1000, (3)~Their location must be in United States, Canada, United Kingdom, Australia, or New Zealand.
Over what Timeframe was the data collected?
Training data was collected from 2017-12-02 to 2018-04-19.
Test data was collected from 2018-05-05 to 2018-06-15.
Is there Information Missing from ReDial and Why?
We removed dialogues which contained offensive content or meta-discussion about the task, as well as unfinished dialogues.
Interface
| Recommender Interface | Seeker Interface |
 |
 |
Data Preprocessing
What Preprocessing and Cleaning was done?
The released dialogues were not preprocessed. However, dialogues were removed if they did not adhere to our guidelines (e.g. swearing, off-topic discussions).
Distribution
If you use ReDial in your research, please cite our paper with the following BibTeX entry
@inproceedings{li2018conversational,
title={Towards Deep Conversational Recommendations},
author={Li, Raymond and Kahou, Samira Ebrahimi and Schulz, Hannes and Michalski, Vincent and Charlin, Laurent and Pal, Chris},
booktitle={Advances in Neural Information Processing Systems 31 (NIPS 2018)},
year={2018}
}
License
The data is published under the CC BY 4.0 License.
Maintenance
Who is Hosting/Maintaining ReDial?
For maintenance-related enquiries, please contact us at the redial google group.
Will ReDial be Updated?
We are considering collecting additional data, but haven’t decided on it.
Legal + Ethical Considerations
How were Participants informed about the Data Collection?
Before working on a task, participants were presented with a consent form describing the methodology and purpose of the data collection.
Was there an Ethical Review?
The data collection was approved by the Comité d’éthique de la recherche avec des êtres humains, Polytechnique Montreal, on 2017-10-27.
If it relates to people, were they told what the dataset would be used for and did they consent?
Workers had to confirm a consent form before every task that explains what the data is being collected for and how it is going to be used.
Does the dataset contain information that might be considered inappropriate or offensive?
Some movie titles contain R-rated language or other triggers. We made an attempt at removing inappropriate dialogues, but cannot guarantee that we identified every such instance.